| Buchdigitalisierung mit Linux und freier Software Eine Anleitung (Stand: 2020) |
| Es gibt viele Bücher, die historischen oder persönlichen Wert haben, die jedoch bisher nicht digitalisiert wurden. Wer nun befürchtet, daß diese Bücher auseinanderfallen und kaputt gehen, ohne daß ihr Inhalt für die Nachwelt erhalten wird, kann diese selbst mit einer ganz normalen technischen Ausstattung von zu Hause aus digitalisieren.
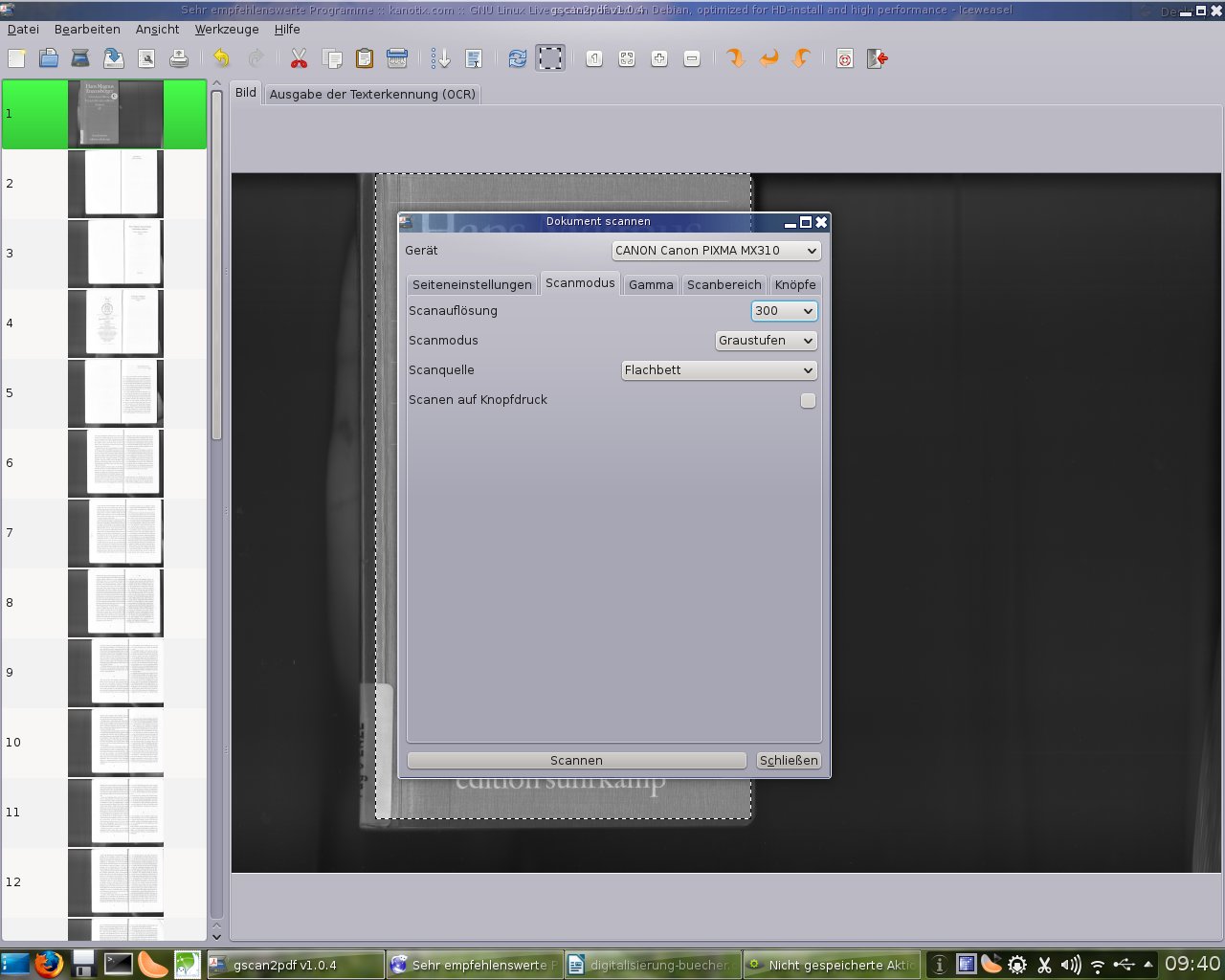
Benötigt wird: Programmpakete: gscan2pdf krename phatch pdfshuffler sane tesseract-ocr tesseract-ocr-deu tesseract-ocr-eng libtesseract4 Bei Debian-basierten Linux-Distributionen ganz einfach Programme so installieren: sudo apt-get update && apt-get install gscan2pdf krename phatch pdfsuffler sane tesseract-ocr tesseract-ocr-deu tesseract-ocr-eng libtesseract4 Weitere Sprachen für das Texterkennungsprogramm tesseract findet ihr hier. Sie können über die Paketverwaltung installiert werden und stehen im Scanprogramm gscan2pdf dann im Auswahlmenü zur Verfügung (siehe Abbildung 13)
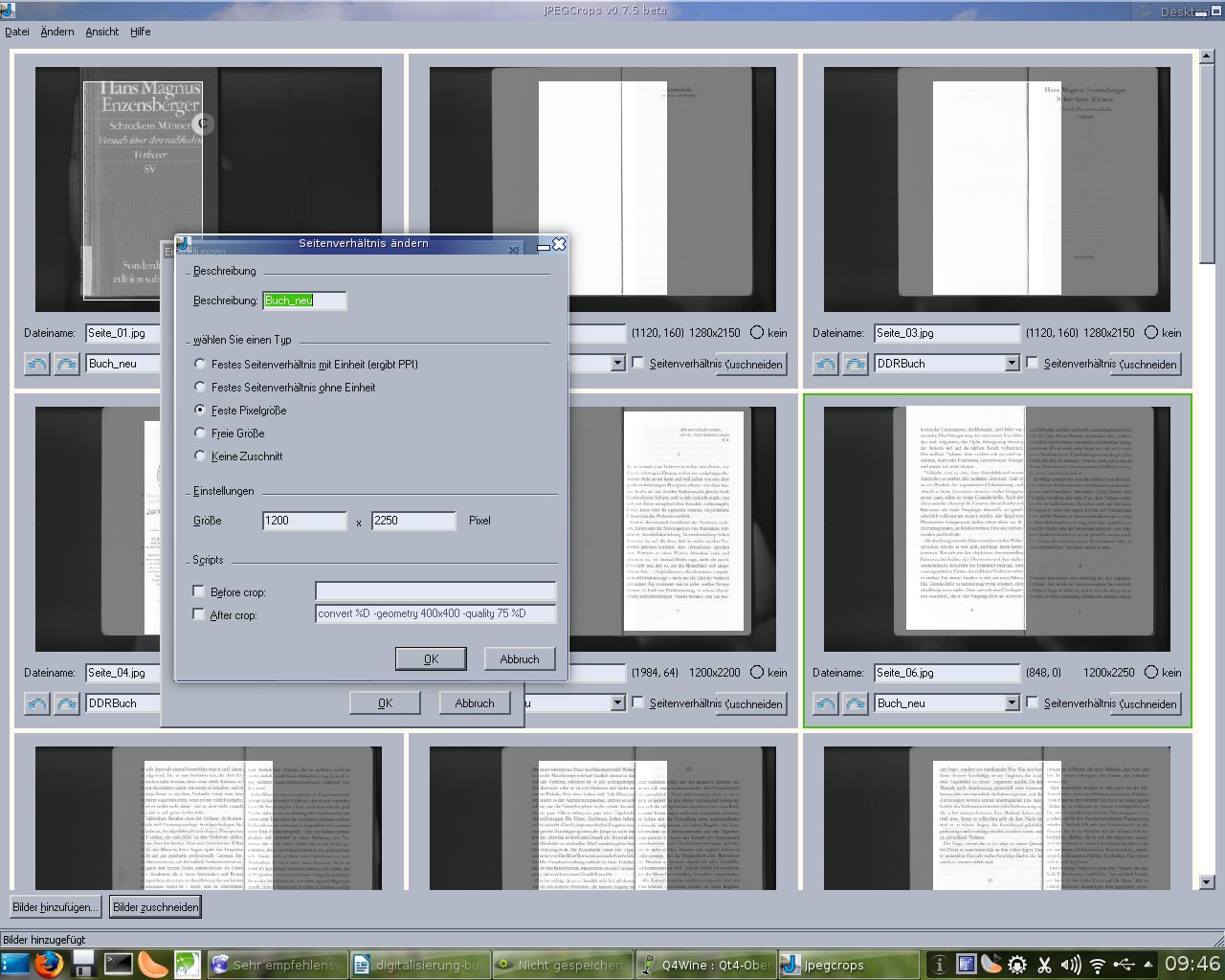
Im Folgenden nun eine bebilderte Anleitung, wie am besten vorzugehen ist. 1. Buch mit gscan2pdf einscannen: Flachbett-Modus „Alle Seiten“. 300 dpi dürfte in der Regel ausreichen. Bei Büchern mit vielen Seiten aufgrund möglicherweise limitierten Speicherplatzes auf der Systemfestplatte, Buch in mehreren Etappen scannen, abspeichern und Programm jeweils neu starten. Oder den temporären Ordner von gscan2pdf auf einen anderen Ordner auf einer größeren Partition/Festplatte ändern. 2. Fertig gescannte Seiten in gscan2pdf als PNG oder als JPG abspeichern. Gscan2pdf nummeriert die Bilddateien automatisch nach dem Dateinamen hoch. 3. Die Gespeicherten Doppelseiten, die zuvor mit gscan2pdf abgespeichert wurden, dann zum Trennen im Programm JPEGCrops öffnen. Man könnte die Buchseiten zwar auch in gscan2pdf beschneiden, allerdings ist es meist so, daß das Buch beim Einscannen nicht immer auf der selben Stelle auf dem Scanner liegt. Wenn man diese Seiten auf den Bilddateien dann alle an der gleichen Stelle ausschneiden möchte, hätte dies zur Folge, daß einige Seiten abgeschnitten werden. Daher sollte man ein alternatives Programm zum Beschneiden verwenden. Am besten eben JPEGCrops. Hier kann die Ausschneide-Größe sehr einfach für jede Seite justiert werden. Und zwar immer mit der exakten Pixelzahl. Diese Größe am besten etwas kleiner als die Größe der tatsächlichen Seite wählen. Hauptsache nichts vom Text wird abgeschnitten. 4. In den Einstellungen ein neues Profil für das aktuelle Buch erstellen und „Feste Pixelgröße“ auswählen. Hier etwas experimentieren, bis man die richtige Dimension gefunden hat, die auf alle Seiten paßt. Klickt man nun auf „Bilder zuschneiden“ speichert JPEGCrops alle Bilder beschnitten im Quellordner. Diesen Vorgang dann zwei Mal wiederholen. Einmal für alle ungeraden Seiten und einmal für alle Geraden. Damit man nicht durcheinanderkommt, lohnt es sich zwei Ordner anzulegen „gerade“ und „ungerade“. In beide Ordner alle Doppelseiten-Dateien kopieren und in zwei getrennten Vorgängen voneinander in JPEGCrops beschneiden. Anschließend die Dateien richtig benennen, so daß sie in der richtigen Reihenfolge bestehen. Hierzu das Programm krename verwenden:
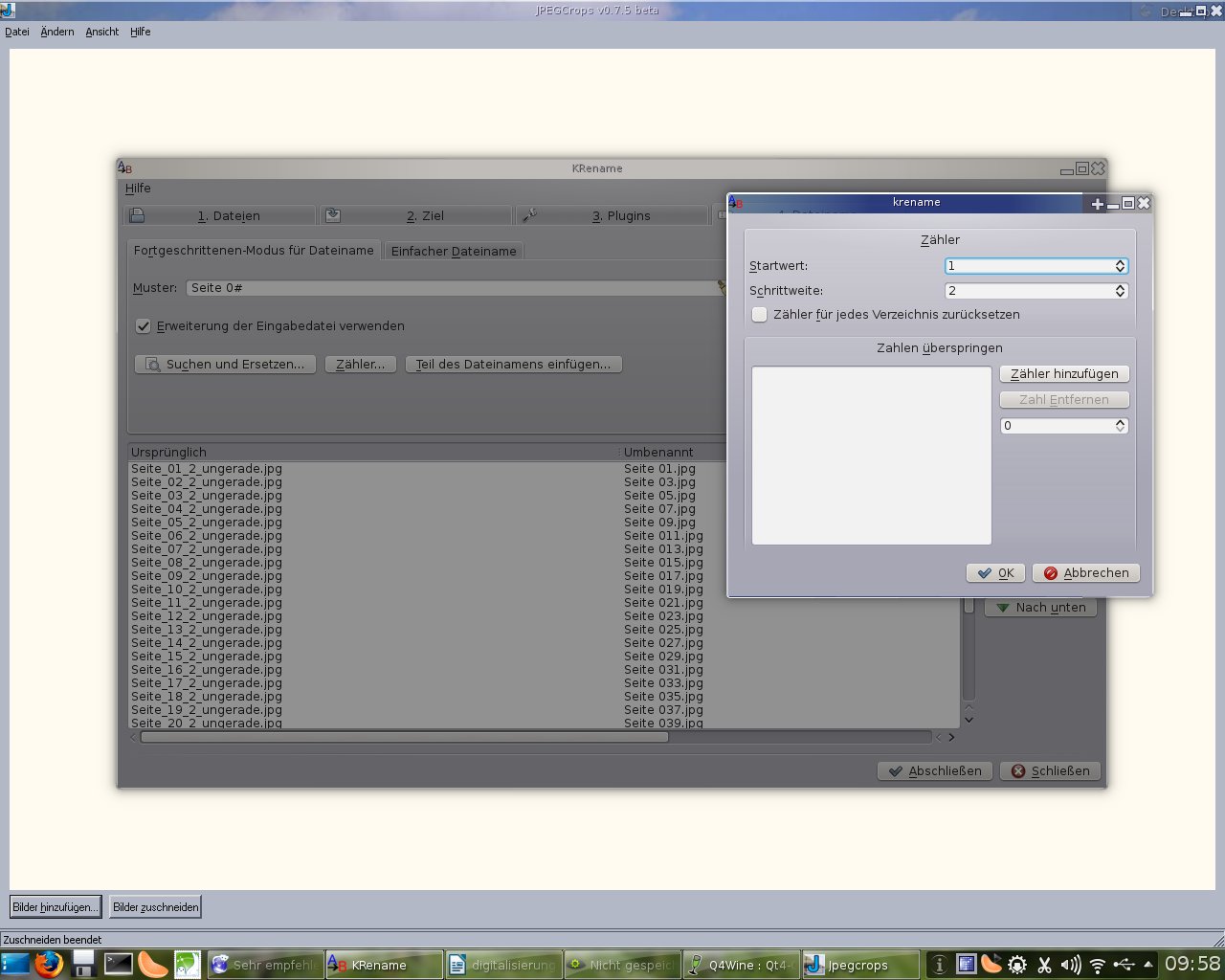
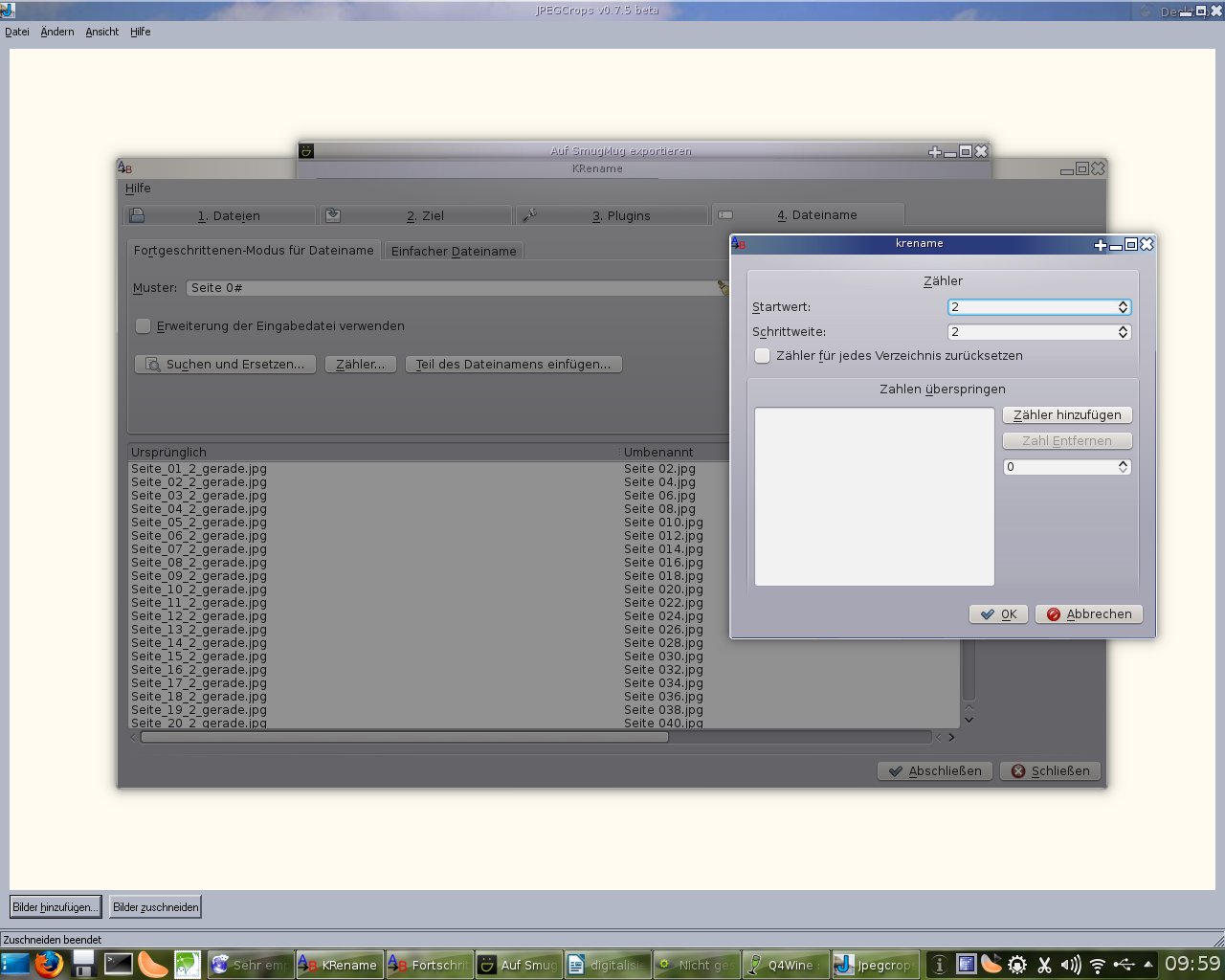
5. Alle Dateinamen der Dateien im Ordner „ungerade“ mit krename um „ungerade“ ergänzen. Das selbe mit allen Dateien im Ordner „gerade“ tun und alle Dateien in einen gemeinsamen Ordner verschieben. Nun kann man mit krename die „Zähler-Funktion“ verwenden. Da ja jeweils eine Doppelseite mit gerade und ungerade gespeichert wurde (Seite 1 und Seite 2; Seite 4 und Seite 5 usw.), und diese Numerierung sowohl für ungerade als auch für gerade Seiten identisch ist, muß bei allen geraden Seiten das Wort „gerade“ mit aufsteigenden geraden Zahlen ersetzt werden. Ebenso bei allen „ungeraden“ Seiten das Wort „ungerade“ mit aufsteigenden ungeraden Zahlen. In der Zähler-Funktion muß man nun also als „Startwert“ jeweils 1 einstellen und unter „Schrittweise“ 2. Das heißt, krename benennt die Dateien so um, daß immer jede zweite Nummer vergeben wird. Also für die Ungeraden Seiten Zahlen von 1,3,5,7… und für die Geraden 2,4,6,8…
Ist die Benennung nun abgeschlossen, sind alle Seiten ordentlich getrennt. So wie in der folgenden Grafik aufgeführt:
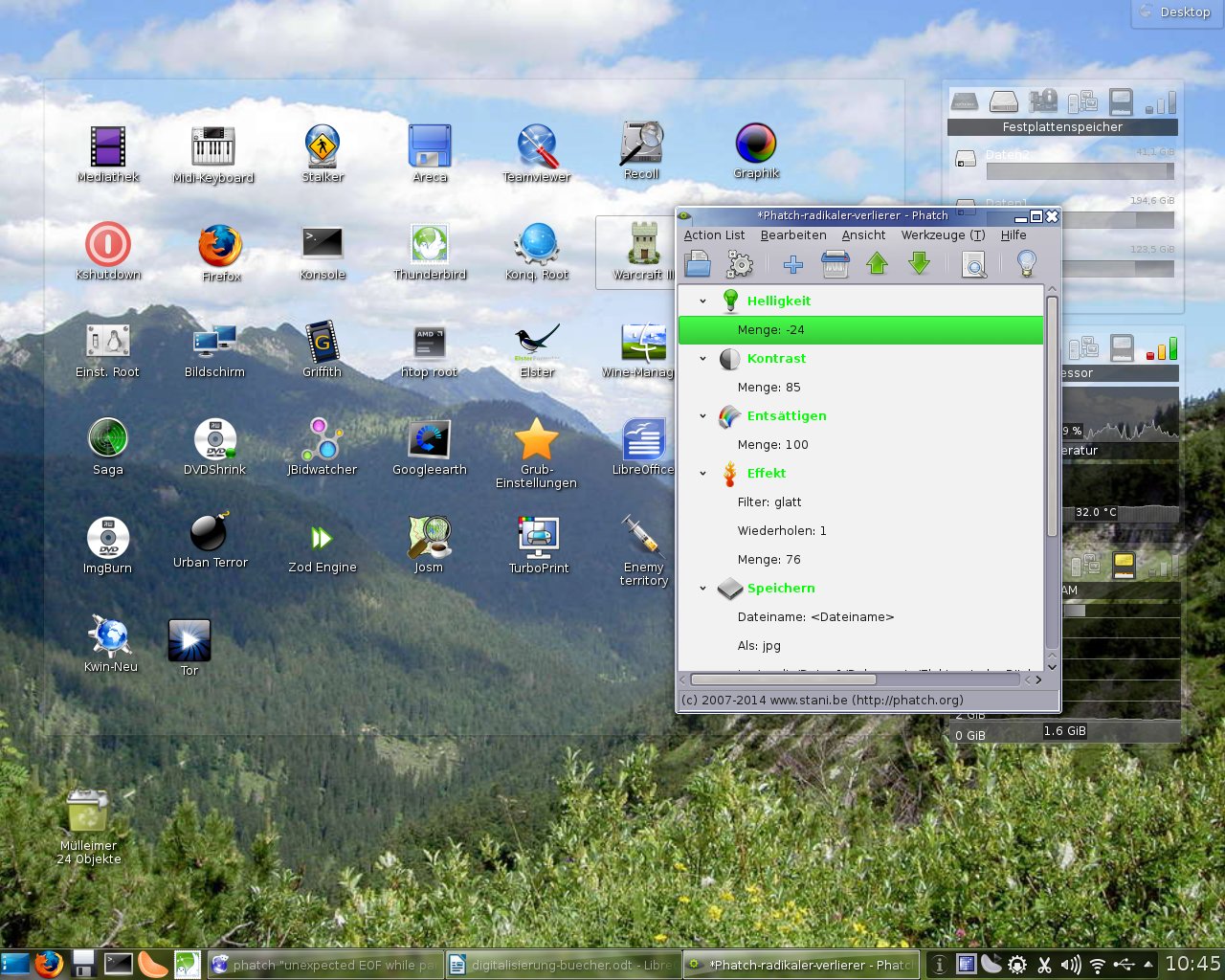
6. Die Numerierung stimmt nun, also können die Dateien noch bearbeitet werden, damit sie nicht so grau und alt aussehen. Hierfür das Programm phatch starten. Am besten einfach diese Vorlage herunterladen und in das Programm einladen. Die Vorlage ist von mir erstellt und am besten für ein etwas älteres Buch aus den 1980er Jahren geeignet, das leicht angegilbt ist und ein normales Buchformat hat. Man muß vermutlich etwas nachjustieren, um für das eigene Scanprojekt die optimalen Einstellungen zu finden. Wenn man sowohl farbige, als auch schwarz-weiß-Seiten im Buch hat, diese am besten getrennt voneinander mit phatch bearbeiten, zumal die Einstellungen hier in der Regel abweichend sein sollten.
7. Phatch ist etwas gewöhnungsbedürftig, dennoch aber ein tolles Programm. In der Liste aufgeführt sind alle Bearbeitungsfunktionen, die auf die Bilder losgelassen werden sollen. Sind die Einstellungen gut, zieht man die Listen der Bilddateien per drag&drop in phatch hinein und klickt auf „Stapelverarbeitung“. Dort wird angezeigt, wo die Dateien gespeichert werden (kann man unter „Speichern“ auch einstellen). Ist man mit dem Ergebnis nicht zufrieden, einfach Einstellungen ändern und Vorgang wiederholen. Bilder nach dem Verarbeiten mit phatch wieder in gscan2pdf hineinladen:
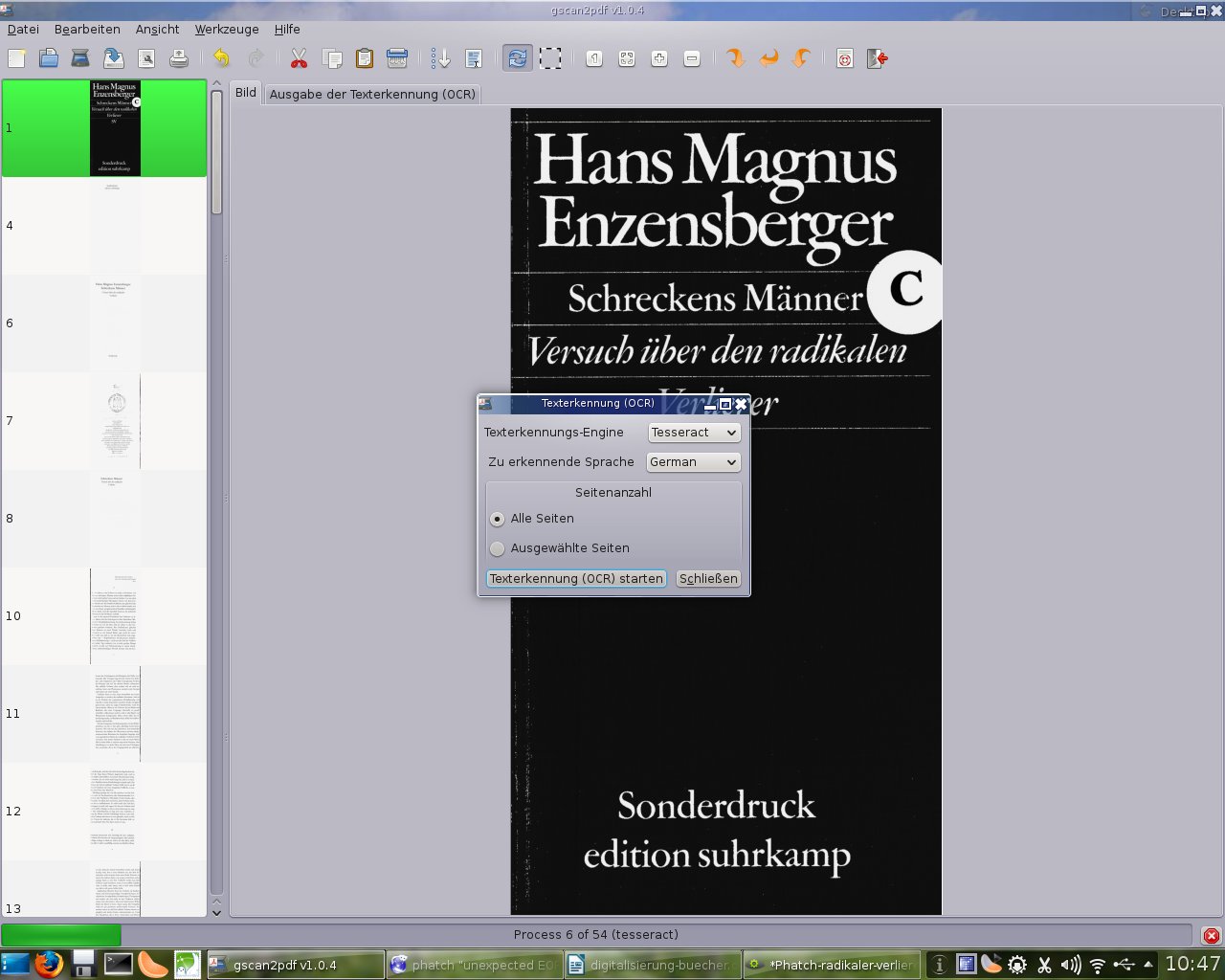
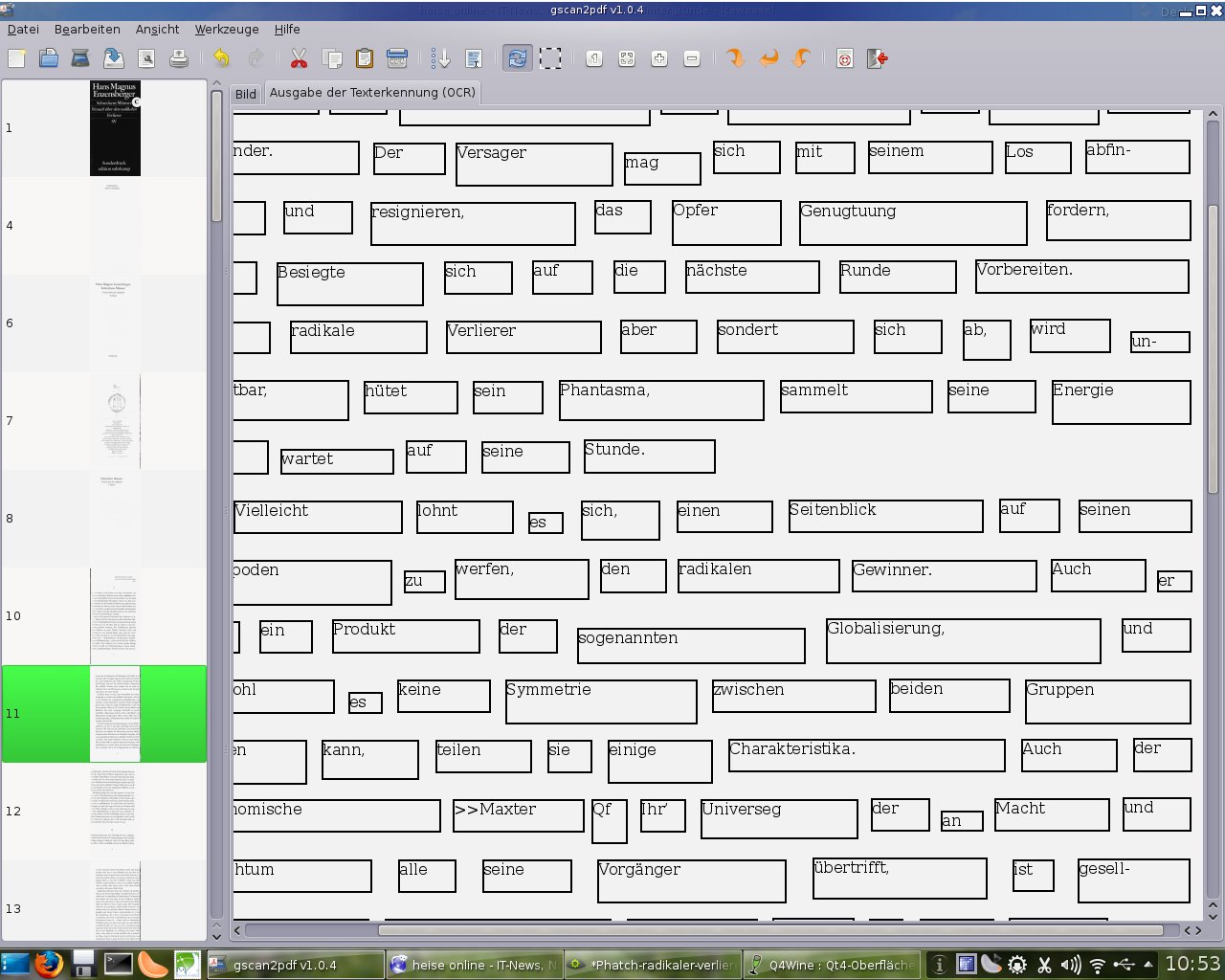
8. In gscan2pdf unter „Werkzeuge“ auf „Texterkennung (OCR)“ klicken und hier als Engine tesseract und die Sprache der einzuscannenden Dokumente auswählen:
Nach dem Durchlaufen der Texterkennung ist das Ergebnis unter dem Reiter „Ausgabe der Texterkennung“ zu begutachten:
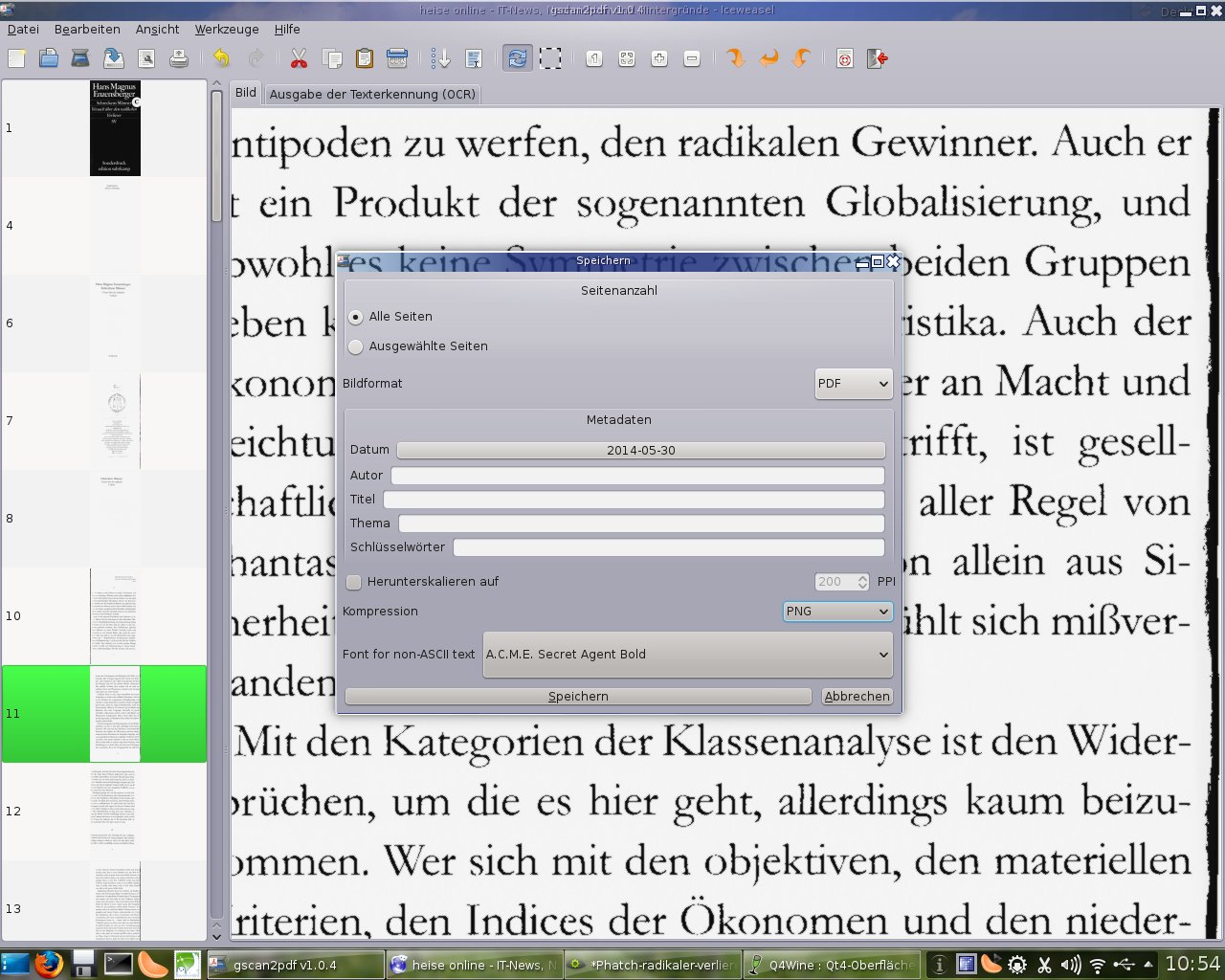
9. Aus gscan2pdf das fertige Buch als PDF-Datei abspeichern. In Bezug auf Dateigröße und Auflösung experimentieren – je nachdem, welche Qualität gewünscht wird. Am besten immer eine qualitativ hochwertige Version mit voller Auflösung und eine kleinere Version abspeichern:
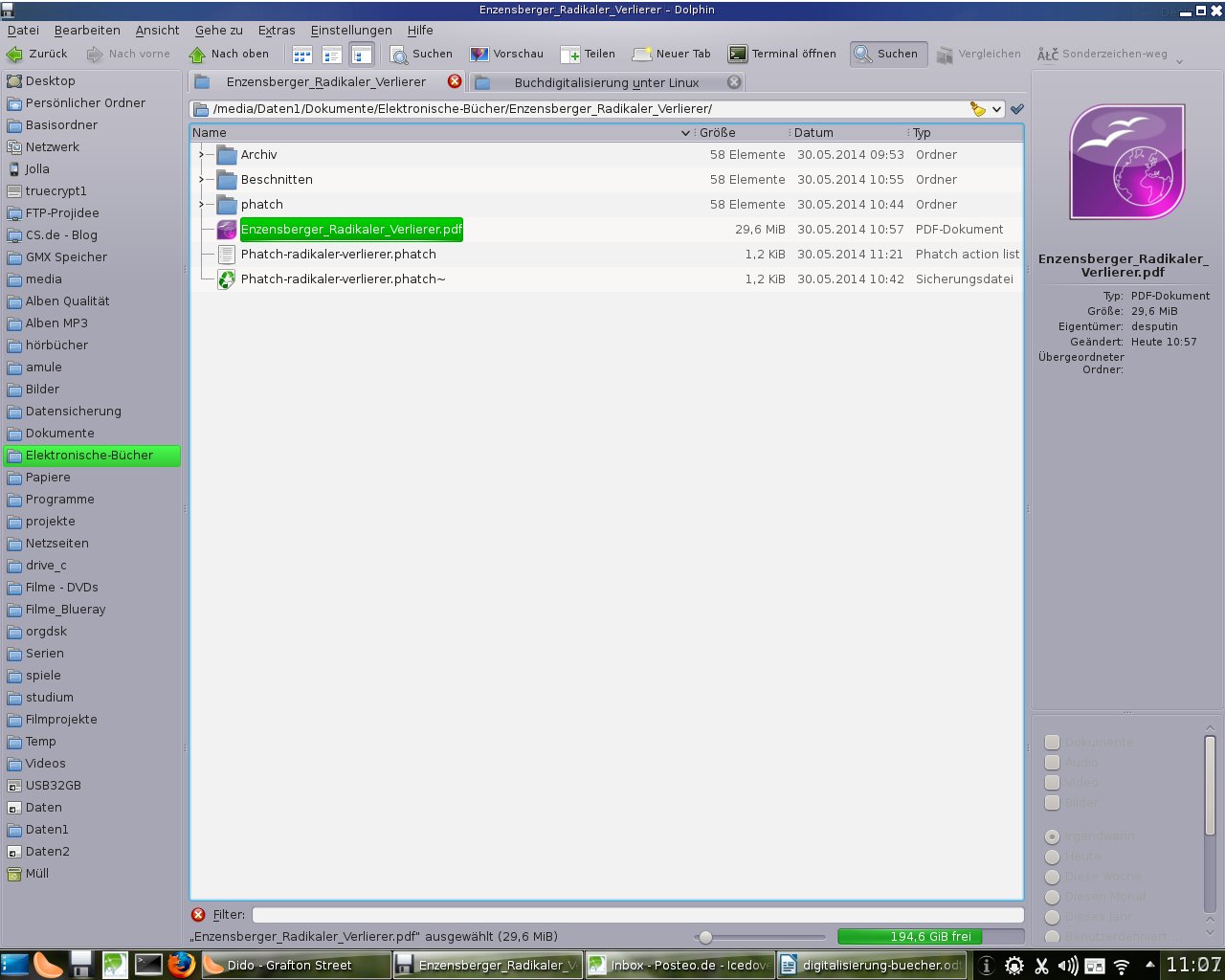
Und fertig ist das eingescannte Buch:
|
3 Antworten auf Ein Buch digitalisieren